
Indexes into Relational Databases
A database index is a data structure that improves the speed of data retrieval operations on a database table (increase database performance). But such performance has a cost of additional writes to hard drive and storage space to maintain the index data structure. In nutshell, index is a quick path to a single row into database. Indexes allow us to go directly to he required column without scanning the entire database table. In real life a good example of what index is could be book index, which has a list of keywords and page numbers where keyword is mentioned.
Index(s) could be created for one or more table’s columns. When index is created it will be updated every time when new data inserted, updated or deleted.
At first place creating indexes for all table’s columns may look as a good idea. But it may impact significantly on database performance on INSERT, UPDATE and DELETE operations. Also indexes require additional disk space.
Create index
The basic syntax for creating index looks into the following way:
CREATE INDEX IF NOT EXISTS index_name ON table_name(column_name)
where
index_name- the name of the index to be create.table_name- the name of the table which to be indexed.column_name- the name of the table’s column for which index to be created.IF NOT EXISTSparameter tells PostgreSQL to create index in case when index with specifiedtable_namename doesn’t exist. In case when this parameter is not specified and index with nameindex_namealready exists error will be throw.
Let’s assume we have avehicle table:
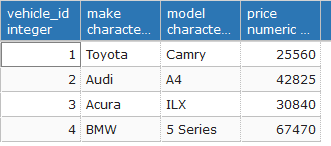
which could be created with the following script:
CREATE TABLE vehicle (
vehicle_id SERIAL NOT NULL,
make VARCHAR(100) NOT NULL,
model VARCHAR(100) NOT NULL,
price NUMERIC(5) NOT NULL
);
INSERT INTO vehicle (make, model, price) VALUES ('Toyota', 'Camry', 25560);
INSERT INTO vehicle (make, model, price) VALUES ('Audi', 'A4', 42825);
INSERT INTO vehicle (make, model, price) VALUES ('Acura', 'ILX', 30840);
INSERT INTO vehicle (make, model, price) VALUES ('BMW', '5 Series ', 67470);
Now let’s create index for the column make using the query mentioned above:
CREATE INDEX IF NOT EXISTS make_indx ON vehicle(make);
If we take a look at table in pgAdmin we’ll see the following:
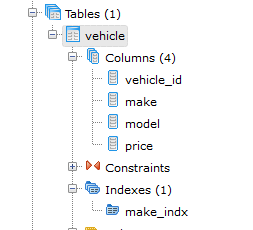
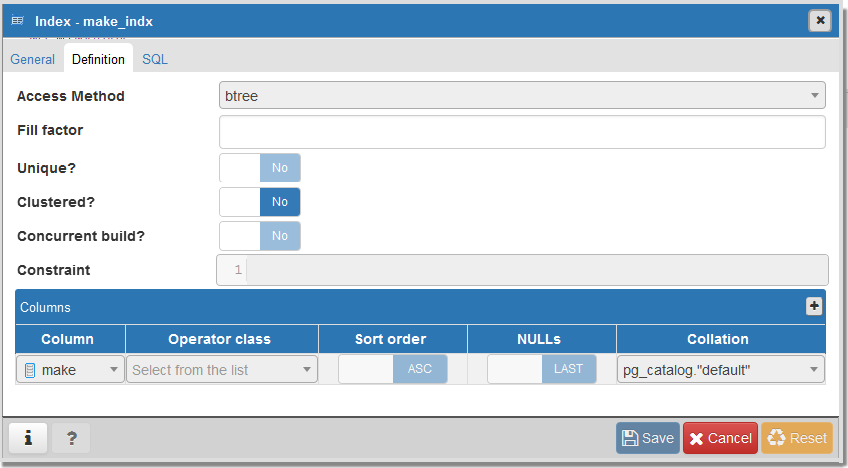
By default the index is created with the following properties:
where
acess method- the name of the index method to be used. PostgreSQL supports the following methods:btree,hash,gist,spgist,gin, andbrin.btreeis used by default.unique- doesn’t allow PostgreSQL to create duplicated indexes. In case when we have 2 duplicate records intovehicletable an exception will be thrown during index creation.concurrent build- tells PostgreSQL to build the index without taking any locks that prevent concurrent inserts, updates, or deletes on the table; whereas a standard index build locks out writes (but not reads) on the table until it’s donecolumnsarea show columns for which index is created.
The full syntax for creating indexes into PostgreSQL looks into the following way:
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON table_name [ USING method ]
( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ WITH ( storage_parameter = value [, ... ] ) ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ]
Detailed description of parameters for creating index could be found at the official PostgreSQL documentation: Create Index.
Delete index
Index could be deleted into the following way:
DROP INDEX index_name;
This query deletes only indexes with name index_name and doesn’t affect the rows of the table. But in case when table has a lot of data deleting index can take long time and can affect the database’s performance.
Index architecture/Indexing Methods
PostgreSQL support the following index types:
- single-column
- multi-column (composite)
- partial
- unique
- expression index
- concurrent index
Single-column index
Single-column index - is an index which is created based on one column of the table. This index type is used when a table represents mostly a single category of data, or queries span around only a single category in the table. Here’s an example for creating single-column index:
CREATE INDEX indx_name ON table_name(column_name);
By default index is created in ascending(ASC) order. To change the order to the descending(DESC) order DESC keyword should be placed right after the column name:
CREATE INDEX indx_name ON table_name(column_name DESC);
Multi-column (composite) index
Multi-column or composite index is an index created based on 2 or more columns. Such index could be created into the following way:
CREATE INDEX indx_name ON table_name(column_name1, column_name2);
Composite indexes are mostly used in case when 2 or more columns are frequently used in filter conditions of query’s WHERE clause.
Multi-column are also created into ascending order by default. To change column’s order to descending, DESC keyword should be add right after the required column name. Each column can have its own order:
CREATE INDEX indx_name ON table_name(column_name1 DESC, column_name2 ASC);
Implicit index
Implicit index is an index which is automatically created by database for primary keys and unique constraints.
Partial (filtered) index
Partial or filtered index is an index which has some condition applied to it so that it includes a subset of rows in the table. Such indexes could be a good choice in case when the subset of table is used is queries.
Partial index could be created using WHERE keyword:
CREATE INDEX index_name ON table_name (column) WHERE (condition);
Let’s assume we added extra column year in our vehicle table, which will store the information about when the vehicle was manufactured:
CREATE TABLE vehicle (
vehicle_id SERIAL NOT NULL,
make VARCHAR(100) NOT NULL,
model VARCHAR(100) NOT NULL,
year NUMERIC(4),
price NUMERIC(5) NOT NULL
);
And let’s suppose we need to retrieve only vehicles which were manufactured after year 2005. In that case partial index is a good choice. We can create partial index into the following way:
CREATE INDEX vehcile_partialIndx ON vehicle(year) WHERE
(year< 2005);
Unique index
Unique index is an index which enforces uniqueness of the column. Such index could be created on any column. We can’t create unique index on column(-s) which has duplicated records. Also we can’t insert duplication into the table, after unique index has been created.
Unique index could be created into the following way:
CREATE UNIQUE INDEX item_unique_idx ON item (item_id);
Also unique index is explicitly created for primary keys.
Concurrent index
Concurrent index is an index which is created without taking any locks that prevent concurrent inserts, updates, or deletes on the table. This index could be used on sizeably huge table because it can take hours to build an index for such table.
Concurrent index could be created into the following way:
CREATE INDEX CONCURRENTLY index_name ON table_name(column_name);
Index Types(methods)
PostgreSQL support the following index methods:
- B-tree
- Hash
- GiST
- GIN
Different index types have different purposes(see below)
B-tree index
B-tree index is effective for query with range and equality operators like (<, <=, >, >=, BETWEEN, and IN). Also this index can be used to retrieve data in sorted order. This is not always faster than a simple scan and sort, but it is often helpful.
CREATE INDEX index_name ON table_name USING BTREE(column_name);
Hash index
Hash index is effective for queries with simple equivalent operators (=) only.
Hash index can be created into the following way:
CREATE INDEX index_name ON table_name USING HASH (column_name);
GiST index
Gist or The Generalized Search Tree index provides the possibility to create custom data types with indexed access methods.
It additionally provides an extensive set of queries.
GIN index
GIN or Generalized Inverted Index is used for handling cases where the items to be indexed are composite values, and the queries to be handled by the index need to search for element values that appear within the composite items. For example, the items could be documents, and the queries could be searches for documents containing specific words.
A GIN index stores a set of (key, posting list) pairs, where a posting list is a set of row IDs in which the key occurs. The same row ID can appear in multiple posting lists, since an item can contain more than one key. Each key value is stored only once, so a GIN index is very compact for cases where the same key appears many times.